


MIT Computer Science Course: Exhaustive enumeration, approximate solutions and the Bisection Search Algorithm with Python

Hello readers! I have been taking an immersive Computer Science course through MIT that is way more intense than I originally anticipated but still a ton of fun! The goal with this course is to further my base knowledge and understanding of core computer science fundamentals and algorithms. I am in Week 3 of the course so far and I wanted to add a little bit to what we have been covering.
First, we started with exhaustive enumeration:
Take small steps to generate guesses in order
Check to see if the result is close enough
Starting with a guess and incrementing by a small value
|guess3|-cube <= epsilon for some small epsilon.
Epsilon acting as the margin of error which serves as the threshold to find our closest match.
For example, you could have your epsilon as .08, meaning that if the number ended up within that value and 0, you have your match
What are some problems here?
Decreasing the increment would find a very accurate answer at the cost of performance
Increasing the epsilon would increase performance at the cost of accuracy
Let's check out the code!
cube = 27
epsilon = 0.01
guess = 0.0
increment = 0.0001
num_guesses = 0
while abs(guess**3 - cube) >= epsilon:
guess += increment
num_guesses += 1
print('num_guesses =', num_guesses)
if abs(guess**3 - cube) >= epsilon:
print('Failed on cube root of', cube)
else:
print(guess, 'is close to the cube root of', cube)
What is a better way of doing this? We know that we need to iterate through multiple values or possibilities to find the closest match to the cube root of 27. This is where the Bisection Algorithm comes into play!
We know that the square root of x lies between 1 and x, from mathematics
Rather than exhaustively trying things starting at 1, suppose instead we pick a number in the middle of this range
Bisection search works when value of function varies monotonically with input
If g, the users input/guess, is less than/greater than the midpoint of the range, then that number becomes the new high point of said range and is then factored into the new search.
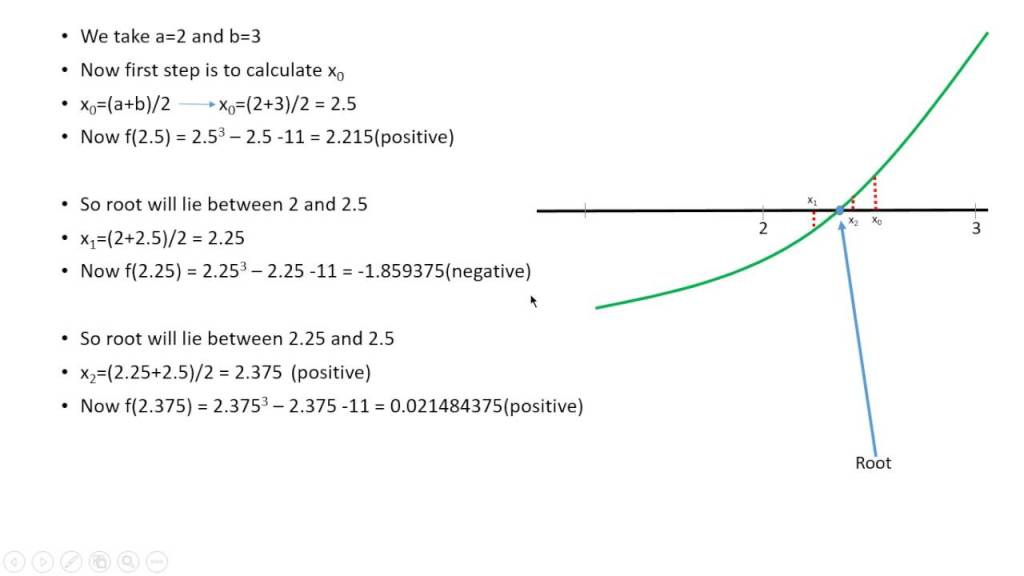
Let's take a look of how we accomplish this in Python and a game that I built using bisection.
low = 0.0
high = 100.0
ans = round((low + high) / 2)
print('Please think of a number between 0 and 100!')
while True:
print('Is your secret number? ', ans);
result = input('Enter "h" to indicate the guess is too high. Enter "l" to indicate the guess is too low. Enter "c" to indicate I guessed correctly.')
if (result == 'c' or result == 'l' or result == 'h'):
if result == 'l':
low = ans
elif result == 'h':
high = ans
else:
print('Game over. Your secret number was ', ans)
break
ans = round(((high) + low)//2.0)
else:
print("Sorry, I did not understand your input.")
continuehttps://videopress.com/v/fjlegXCa?preloadContent=metadata
Isn't that so cool?! Before in our attempt to use exhaustive enumeration, you can see that we had a little under thirty thousand guess attempts before we got the right answer. Not a terrible way to solve a problem, however not the most efficient either! In this example, the number I chose was 83. As you can see, with bisection it took us about 7 tries before we were able to find the correct number. If we can identify which range of numbers are relevant to our solution, we can just throw the remainder out and focus on what matters. This algorithm is very powerful and a wonderful way to incorporate high performance and accuracy into your application.
I will be sharing more as the class continues! Please let me know if you have any questions on these concepts as they are covered. Happy coding!